
Introduction to Patterns of Information Management

get the book here
Islands of Information
Most organizations use specialized IT systems called applications to run their operations. Each application supports a particular aspect of the business, either for the whole organization or a group within it. There may be applications for order taking, for billing, for distribution of goods, for management of employee data, and many more.
An application will store the information it is processing in a persistent store for later reference. This information store is often a private resource for the application. Over time, this store contains important details about the people with whom the organization is interacting, what assets they use, how, when, and why.
A healthy organization will develop and grow—and this change drives changes into its applications, affecting their function and scope. It can also lead to duplication of function:
- When two organizations merge, they can end up with at least two applications for each function.
- When a new product line or channel to market is introduced, an organization may choose to introduce a new application to support it, to avoid the possibility of disrupting the established business or to implement it faster.
- Multinational organizations find they need separate applications for different countries, or trading regions, to handle local customs and regulations.
Careful management and constant rationalization may reduce the number of applications so there is little or no overlap in function. However, an application is a complex mix of software and hardware. It takes considerable engineering effort to develop it, and so once the investment is made, an application is expected to have a long life (5–15 years). Ripping it out and replacing it can be expensive and difficult and so an organization may choose to maintain multiple applications for the same function.
When there are two applications covering the same function, information about that function is split between the two applications and is typically stored in a different format. Even when all applications support unique functions, there is still an overlap in the information that they hold. This is the information that describes the core interests of the organization, such as customers, suppliers, products, contracts, payments, assets, employees, and many more.
Over time, the private information stores of an organization’s applications become islands of duplicated and inconsistent information. This affects the efficiency of an organization and its ability to operate in a cost-effective, flexible, and coherent unit.
This book seeks to address the challenge of effective information management. How does an organization improve its management of information, working with the applications it already operates, to ensure it knows what its assets are, what it is working on, what commitments it has agreed to, how well it is performing, and how it can improve its operation?

Introducing MCHS Trading
MCHS trading is a fictitious trading company used in this book to illustrate different approaches to information management. MCHS Trading sells goods through four channels: on the Internet, via mail order, via a call center, and through physical shops. Due to differences in requirements, orders are taken by three different applications: E-shop for the Internet orders, Mail-shop for mail order and the call center, and the Stores application to support the needs of the physical stores. These applications were introduced incrementally as MCHS Trading opened the new channels to its customers.
Orders are fulfilled and money is collected through the Shipping and Invoicing applications, respectively. The E-shop, Mail-shop, and Stores applications send the order details to the Shipping application, which in turn forwards them on to the Invoicing applications as soon as an order is dispatched. This is illustrated in Figure 1.1.
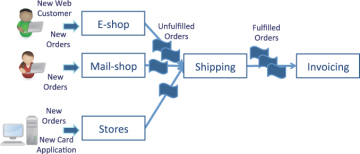
Figure 1.1. MCHS Trading’s order-processing systems.
From a functional point of view, this is a rational separation of concerns. Each application has a clearly delineated set of responsibilities and the process works—customers get the goods they ordered and the correct money is collected in exchange for the goods.
However, when the information stores are added to the picture (see Figure 1.2), you can see that the details about customers, products, and orders are replicated across the systems. Why? Because this information is core to MCHS Trading’s business and so every application needs it in some form or another.
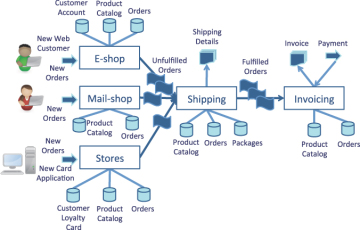
Figure 1.2. Information stores supporting order processing.
Failing to synchronize this information effectively leads to inflexibility and inefficiencies in the organization that can have an impact both internally and externally.
Consider an individual customer, Alistair Steiff. He has registered for a loyalty card, which is handled by the Stores application, and he also uses the E-shop and the mail order channel from time to time. The E-shop keeps a record of Alistair in the form of a customer account. This is different from the loyalty card account. The Mail-shop application takes Alistair’s details with each order. It has no capability to maintain his details for the next time he orders something through that channel, which Alistair finds a little annoying.
Alistair experienced another issue when he moved to a new address. Although he updated his address in his E-shop account, MCHS Trading kept sending his loyalty card statements to his old address. He tried phoning MCHS Trading’s call center but they could not help because they were only set up to take new orders. He had to write a letter to MCHS Trading to get the loyalty card address updated.
Within MCHS Trading, there is also frustration with the current systems. It is difficult to understand the buying patterns of its customers:
- To understand which new products would be of interest to an individual
- To understand how an individual interacts across each of MCHS Trading’s sales channels
There are two issues here. First, the applications only store information that is relevant to their operation—so it is hard to see the complete picture when the details are spread among the applications. Second, applications are designed to reflect the current operational state of their work. They may keep historical data, but not in the form that is conducive to analysis of trends and anomalies.
Want to Earn daily 500 to 800 USD
by selling High demand &
Ultra modern and novel Gadgets online ?
This lack of insight is inhibiting MCHS Trading’s ability to grow and there is a need to introduce new management reporting capability to understand how the business is really performing.
Improving an Organization’s Information Management
The problems that MCHS Trading is experiencing are typical for many organizations. Information is distributed across multiple applications for operational efficiency, leaving the information duplicated, fragmented, and often inconsistent. As a result, the organization cannot act in a coordinated manner:
- They find it hard to get an overall picture of how well the organization is performing. This requires a consolidated view of their business activity, showing the current position, along with a historical perspective for comparison. For example, MCHS Trading would want to understand how many customers it has, what types of products its customers are interested in buying, how this is changing over time, how efficient the delivery process is, who its best suppliers are, and much more if it is to maintain its market leadership position.
- The quality of information varies from application to application. This means different parts of the organization are operating on different facts that could lead to different decisions being made for the same situation.
- The internal fragmentation of the information is often exposed outside of the organization, creating poor customer service or missed opportunities. This was Alistair Steiff’s experience when he tried to change his address—he had to ensure it was updated in each application—using a different process for each one.
- External regulators are skeptical that the organization’s reported results are accurate when ad hoc processes are used to create them because it is difficult to explain where the information came from and how the results were calculated.
- Information is not retained for the required amount of time—or too much information is retained for too long. Either case can inhibit the ability to find the right information in a timely manner.
- Failures in the mechanisms that move information around can corrupt the integrity of the organization’s information. These failures may be errors in the information itself, which means it cannot be transferred, or errors in the implementation of the mechanism, or a failure to initiate some processing in time, resulting in missing information. These failures may not be detected for some time and can be extremely difficult to resolve.
An organization needs to maintain a strong core of information to run the business. This requires a focus on how key information is created, processed, and stored within its IT systems:
- They must optimize where information is located relative to the workload that is using it—ensuring copies are taken in a thoughtful way and these copies are supported with mechanisms to maintain or remove them as new information becomes available.
- Related information should be correlated together to create a complete picture of the organization’s activities.
- Obsolete information must be removed to save storage and reduce the processing effort. Vital historical information needs to be retained.
- Information must be protected from inappropriate use, restored after a failure, and, despite the fact that most organizations have their silos and cliques, the right information needs to be exchanged and presented to the right people at the right time.
This is hard to achieve. Technology is often focused on providing function to the business rather than managing information. Specialist information management technology helps, but it has to be blended with the existing infrastructure. The blending process creates emergent properties.
Emergent properties are those characteristics that “appear” when components are combined together in a particular configuration—rather than being inherent properties of any one of the components. This is similar to the behavior of colors when you mix them together. If you combine blue and yellow, you get the color green. Green is an emergent property because it is not present in either the blue or the yellow—and only emerges when they are combined.
When we combine technology together, we also get emergent properties. These emergent properties may be additive, or they may override some of the components’ original capabilities.
Consider two applications sited on opposite coasts of the United States. The application on the East Coast needs to regularly send information to the West Coast application. However due to the different time zones in which they operate, there is a 3-hour period of its operation when the West Coast application is not available. It is not possible to extend the period of operation of the West Coast application—and the East Coast application is not capable of buffering the information until the West Coast application comes online.
The solution is to provide a new database that is available whenever either application is online (see Figure 1.3). The East Coast application writes information into the database. The West Coast application processes the information in the database when it becomes available.

Figure 1.3. Using a staging area between two applications.
This is a common integration approach. The database in the middle is acting as a staging area. Its effect in the integration is to expand the time window that information can be transferred between the two applications. It may also improve the resiliency of the integration because the East Coast application is no longer affected by the occasional outages of the West Coast application. However, the downside is that when both applications are available, the staging area slows down the transfer of information between the two applications because there is a small delay between the East Coast application writing the information and the West Coast application picking it up. The time it takes to transfer information between two systems is called the latency of the information transfer.
The increased availability, latency, and resilience are all emergent properties of the integration. In general, the emergent properties relate to non-functional characteristics that may not be evident until the integration is in production. This is why architects like to use tried and tested approaches where the emergent properties are well understood.
This book describes how the flow of information between applications and other systems should be designed, calling out the emergent properties as they occur.
The aim is to shape the placement of workload and information stores within the IT systems to create an orderly flow of information that guarantees the quality of the results. The material is presented as a set of connected software design patterns, called a pattern language.
---------------------------------------------------------
Patterns and Pattern Languages
A software design pattern defines a proven approach to solving a problem. The solution described in the pattern is typically a set of components that are interacting in a particular configuration. The pattern explains why this approach works, its associated trade-offs, and resulting benefits and liabilities. It also links to other patterns that may:
- Provide an alternative approach
- Provide a complementary capability
- Describe an approach to implementing a component that is named in the pattern’s solution
This linking together of related patterns creates what we call a pattern language.
Every pattern in this pattern language has a name that summarizes the solution it represents in a succinct manner. For example, there is a pattern called INFORMATION COLLECTION that describes a collection of related information. Notice that the pattern name is written using the small capitals formatting. This formatting convention is used wherever the pattern is first referenced in a section. The name of a pattern can act as shorthand for the solution during design discussions.
Choosing the terminology for the pattern names has been a challenge because the pattern language covers multiple architectural disciplines. Where possible, we have used industry standard names for the concepts and components exposed in the pattern language. However, we have found it necessary to introduce new terminology whenever there is conflicting nomenclature, or no obvious name exists.
Every pattern has an icon that can be used as a visual reminder of the pattern, particularly when whiteboarding and documenting solutions. The information collection icon is shown in Figure 1.4.

Figure 1.4. Icon for the information collection pattern.
The patterns are built on a common component model. This means that a pattern can be used as a component in the solution described by another pattern. When this occurs, the icon of the pattern is used in the solution diagram of the consuming pattern. For example, Figure 1.5 shows the solution for the staging area introduced in the previous section. It is built from a variety of pattern icons.
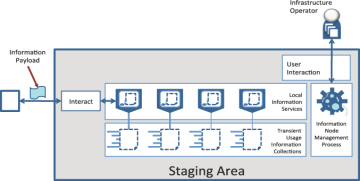
Figure 1.5. The solution diagram for a staging area showing the use of the information collection icon.
The meaning of the icons in the diagram, and the details of the patterns behind them, will become familiar to you as you work with the pattern language. The purpose here is to illustrate how the icon of one pattern, the information collection in this case, can be used in the solutions of other patterns.
Each of the patterns of information management can be used independently. However, the real value of a pattern language is the ability to compare and contrast different approaches to resolving a situation.
The patterns of information management that are relevant to a particular situation are collected together in a pattern group. Each pattern group has a lead pattern that describes the core principles and capabilities of the group. The pattern group is named after the lead pattern. The other patterns in the pattern group enhance one or more characteristics of the lead pattern to support a more specialized situation.
You may have noticed that in Figure 1.5, the information collection icon appears slightly modified in the solution diagram with five lines coming out of the left side (as shown in Figure 1.6). The modification to the information collection icon denotes that the staging area uses specialized information collections described by the TRANSIENT SCOPE pattern.

Figure 1.6. Icon for the transient scope pattern.
The modified icon visually represents that there is a relationship between the information collection and transient usage patterns. They are, in fact, from the same pattern group along with other patterns called LOCAL SCOPE and COMPLETE SCOPE.
To make it easy to compare and contrast the patterns in a group, each group of patterns begins with a table of pattern summaries, called patlets. A patlet shows a pattern’s icon, name, short problem statement, and summary of the solution. The aim of the patlets is to help you quickly discover and navigate to the pattern you need. Table 1.1 shows the patlet for the INFORMATION COLLECTION pattern, which is the lead pattern in its group.
Table 1.1. Sample Pattern Summary for Information Collection
Icon | Pattern Name | Problem | Solution |
| INFORMATIONCOLLECTION | Information must be organized so it can be located, accessed, protected, and maintained at a level that is consistent with its value to the organization. | Group related information together into a logical collection and implement information services to access and maintain this information. |
Table 1.2 shows the related scope patterns from the same group. Notice that the icons are all variations of the information collection icon.
Table 1.2. Patlet Table for the Scope Patterns in the Information Collection Group
Icon | Pattern Name | Problem | Solution |
| COMPLETE SCOPE | An information process needs to perform an activity once for each instance of a particular subject area (such as a customer, product, order, invoice, shipment, etc.) that occurs within the information supply chain. | The information process needs to use an information collection that stores a single information entry for each instance of the subject area that occurs within the information supply chain. Such an information collection is said to have a complete scope. |
| LOCAL SCOPE | The implementations of the information processes hosted within an information node assume they are in complete control of changes to the information they use. | Provide information collections within the information node for the sole use of its information processes. These information collections will then only have information entries that are created by the locally hosted information processes. These types of information collections are said to have a local scope. |
| TRANSIENT SCOPE | An information node needs to provide temporary storage for information entries that are being continuously added and removed by the information processes. | Create an information collection to temporarily store the information entries in the information node. From time to time, the information entries stored in this information collection will change, and so we say this collection has transient scope. |
The detailed pattern descriptions follow the patlet tables. Many different styles and heading structures have been successfully used to describe software patterns. We have chosen to use one of the formats recommended by The Open Group Architecture Framework (TOGAF®)1 with the following subsections:
- Context—The situation where it is appropriate to consider using the pattern
- Problem—A description of the problem that this pattern solves
- Example—An example of the problem
- Forces—The factors that make this problem hard to solve
- Solution—A description of solution components and how they are assembled together
- Consequences—The benefits and liabilities of using the solution
- Example Resolved—How the example described is resolved using the pattern
- Known Uses—References to well-known technologies and approaches that support the pattern
- Related Patterns—Links to other relevant patterns in the pattern language
These sections provide a way to bring together a variety of information into a well-formed structure that summarizes the essence of the pattern. Together, they enable you to make reasoned choices of approach for the solution you are building.
Basic Components in the Pattern Language
A good place to start learning about the Patterns of Information Management is a pattern called INFORMATION PROVISIONING. This describes how five basic components interact to receive, process, and produce information.
Figure 1.7 comes from the information provisioning pattern description and shows the components and how they interact. All of these relationships are many-to-many.
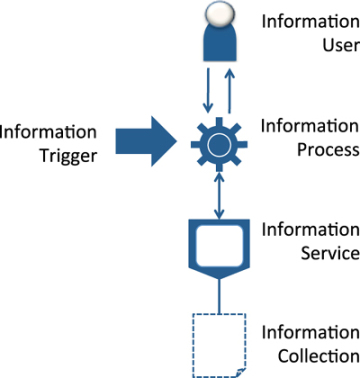
Figure 1.7. Five basic components for processing information.
Notice that the information collection pattern introduced previously is shown as a component in the information provisioning pattern along with some additional patterns: INFORMATION USER, INFORMATION TRIGGER, INFORMATION PROCESS, and INFORMATION SERVICE.
The information user is a person working with the organization’s information. This person may be an employee or someone outside the organization such as a customer or a supplier. Each kind of information user has his or her own requirements for the kinds of information needed, where, and when. The information user is both a consumer of existing information and a contributor of new information. The information user works with user interfaces that are controlled by information processes.
The information processes perform the automated processing of the organization. There are many different kinds of information processes—but, collectively, they are the mechanisms by which information is received, transformed, and produced in some form or another.
An information trigger starts an information process. This may be the result of an information user request, a scheduler, an event being detected, or the need for more information. The information trigger passes the information process some context information that describes why it is being started. The information process augments this context information with information from the information users and other information known to the organization.
An information process accesses any additional information it needs through well-defined interfaces called information services. An information service provides a specialized view of the information that the information process needs. It is able to locate the requested information from a variety of sources and transform it into a format suitable for the requesting information process. An information service retrieves stored information from information collections.
The information collection manages a collection of related information. Typically, the contents of an information collection relate to the same subject area. However, an information collection may contain information that was collected from the same activity, such as the results of an experiment, from the same source, such as readings from a sensor, or from the same time period, such as social media extracted for a specific period of time.
The information provisioning pattern is a lead pattern of a pattern group. It recognizes that the information a person sees through a user interface is different from the way it is stored and shows the layering of components used to manage the mapping. The rest of the pattern group describes how information is provisioned when multiple systems are involved.
Information Integration and Distribution
As already discussed, an organization will have many applications and other kinds of IT systems. Each of these systems will host their own information processes, information services, and information collections.
We use the INFORMATION NODE pattern to represent the general concept of a system. You may want wish to think of this as a physical computer, or server. However, with the increasing use of virtual systems and cloud provisioning, the notion of physical hardware being tied to a particular system is becoming less common. So an information node is simply an identifiable “system” that the organization runs.
The information node is the lead pattern in a large information group that describes different types of systems. The application is represented by a pattern from the group called APPLICATION NODE. The STAGING AREA pattern is also in the same group.
The information node provides an execution environment for the information processes, information services, and information collections. Calls between these components can occur totally within the information node. However, it is also possible for information processes to access information from different information nodes. This capability is provided a specialist pattern within the information service pattern group called REMOTE INFORMATION SERVICE.
Figure 1.8 illustrates this mechanism. The remote information service uses an INFORMATION REQUEST pattern to retrieve information from an information collection located in another information node. The information request pattern consists of two message flows: one from the remote information service to the information node that hosts the information to request the information, and another flowing in the opposite direction to return the requested information.
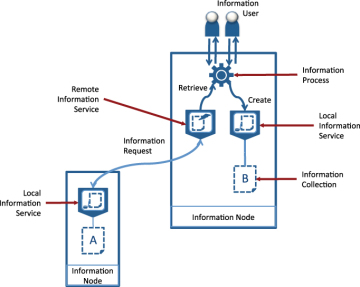
Figure 1.8. Accessing information from a different information node.
The information node that receives the request for information routes it to an appropriate information service to extract the information and return a response. In Figure 1.8, this is shown as a LOCAL INFORMATION SERVICE—that is, one that uses information collections from the same information node—but it could be another remote information service.
The information request pattern retrieves information from its original location on demand. This means both the calling and the called information node must be available at the same time. When information must be copied from one information collection to another—for example, for performance or availability reasons—the information flow pattern is used instead. This introduces another kind of information node called an INFORMATION BROKER that calls remote information services to extract information from one or more information collections, transform it, and store it in other information collections. The effect is that information flows between the information nodes in what we call an information supply chain.
Want to Earn daily 500 to 800 USD
by selling High demand &
Ultra modern and novel Gadgets online ?
Figure 1.9 illustrates this flow of information. The numbers on the diagram refer to these notes:
- Here, an information process calls a remote information service to retrieve information from information collection A. Under the covers, the remote information collection uses an information request to contact the information node where information collection A is located.
- The information process then works with some information users to update the information and store the results in information collection B.
- Information collection B stores the information in a new entry in the information collection.
- An information broker now starts an information process to extract the information from information collection B and transform it and save it as a new entry in information collection C.
- Another information process starts to retrieve the information from information collection C.
- This process may make changes to the information and update it in information collection C.
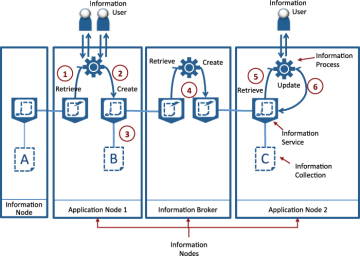
Figure 1.9. Flowing information between systems.
This example illustrates how multiple copies of information are created—and also how these copies quickly become slightly different from one another. The differences could be as follows:
- Superficial—Such as a reformatting
- Enriching—Where additional information is added to the original information
- Localized—Where updates made are only relevant to the location where they are made
- Managed—Where the best source of information (called the authoritative source) is well known at all times
- Conflicting—Where it is hard to know which information collection is the best to use or retrieve the latest information from as changes are coming in to each of the copies in an unpredictable way
A well-defined information supply chain should avoid having information collections with conflicting differences in them. We aim to minimize the number of copies. Where copies are made, each should have a clear purpose and guidelines on when it should be used. Copies should be synchronized when updates are made, and where differences are unavoidable, there should be at least one copy that is known to have all of the latest information in it.
The INFORMATION SUPPLY CHAIN pattern is the lead pattern in a pattern group that describes different patterns of information movement between the information collections and how to synchronize the information to avoid conflicting differences. Designing information supply chains is a key challenge for both information architects and solution architects.
Pattern Language Structure
The pattern groups introduced in the previous sections show the breadth of factors an architect needs to consider to achieve a clean, correct, and flexible information design. At the top of the pyramid, you see the organization and the people who work within it. They drive the information strategy. The organization is supported by the information architecture, which is implemented by the information management components. This structure is summarized in Figure 1.10.
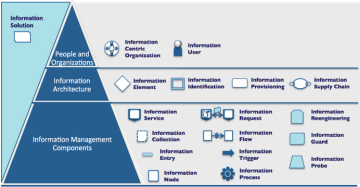
Figure 1.10.Structure of the pattern language for information management.
Chapter 2, “The MCHS Trading Case Study,” contains the case study, introducing the patterns through different projects at MCHS Trading. The remaining chapters contain the pattern descriptions and are organized according to the structure in Figure 1.10.
Chapter 3, “People and Organizations,” has the patterns for the organization and its people (see Table 1.3). These patterns include the information strategy, policy setting, and information governance.
Table 1.3. Pattern Groups in Chapter 3
Lead Pattern Name and Icon | Lead Pattern Problem Statement | Lead Pattern Solution Summary | Start Here When... |
INFORMATION CENTRIC ORGANIZATION | An organization needs to make good use of its information to achieve its goals. | Make the management of information a strategic priority. Develop systems and practices that nurture and exploit information to maximum effect. | You are thinking about the holistic approach that your organization should take to information management. |
INFORMATION USER | Individuals need access to the organization’s information to perform their work. | Classify the people connected with the organization according to their information needs and skills. Then provide user interfaces and reports through which they can access the information as appropriate. | You want to define what types of user roles should be supported by a new information solution. |
Information architects develop an understanding of the information needs of an organization and propose best practices for how it should be structured, stored, and managed. Solution architects are responsible for developing IT-based solutions to business problems. These solutions are dependent on information and so the solution architect relies on the information architecture created by the information architect when developing a new solution. Both the information architect and the solution architect use information architecture patterns in their work. These are described in the pattern groups shown in Table 1.4, and are described in more detail in Chapter 4.
Table 1.4. Pattern Groups in Chapter 4
Lead Pattern Name and Icon | Lead Pattern Problem Statement | Lead Pattern Solution Summary | Start Here When... |
INFORMATION ELEMENT | An organization is looking for the best approach to manage the many kinds of information it has. | Group together related information attributes that follow the same life cycle and manage them appropriately. | You are new to information management and want to familiarize yourself with the types of information an organization has, and how it is managed. |
INFORMATION IDENTIFICATION | An organization does not know what types of information it has, where it is located, how it is managed, and who is responsible for it. | Investigate and document the information requirements and existing support available to the organization. | You want to catalog the information you have and any new requirements. The resulting information is often called metadata. |
INFORMATION PROVISIONING | An information process needs information to perform its work. | Information is supplied to the process when it starts, through its user interfaces and through stored information. | You are considering how to provide information to an information process or information user. |
INFORMATION SUPPLY CHAIN | An organization needs to process information in order to fulfill its purpose. How is the flow of information coordinated throughout the organization’s people and systems? | Design and manage well-defined flows of information that start from the points where the information is collected for the organization and links the flows to the places where key consumers receive the information they need. | You are designing how a particular type of information should flow between your systems. |
Chapter 5, “Information at Rest,” covers the way information is processed within an IT system (see Table 1.5). In this pattern language, a system is called an information node and there is a related pattern group devoted to the various types of systems.
Table 1.5. Pattern Groups in Chapter 5
Lead Pattern Name and Icon | Lead Pattern Problem Statement | Lead Pattern Solution Summary | Start Here When... |
INFORMATION SERVICE | Some information processes need the same information, but may require it to be formatted differently. | Define well-defined interfaces to the information that meet the needs of particular consuming information processes to enable them to create, retrieve, and maintain just the information they need. | You need to decide how an information process will access the information it needs. |
INFORMATION COLLECTION | Information must be organized so it can be located, accessed, protected, and maintained at a level that is consistent with its value to the organization. | Group related information together into a logical collection and implement information services to access and maintain this information. | You need to classify how the existing stores of information are used or decide how new information should be grouped and stored. |
INFORMATION ENTRY | An instance of a type of information needs to be stored in an information collection. | Structure the information collection so that it is made up of a set of information entries. Each information entry stores a single instance of the subject area. Provide capability to manage and iterate over a collection of these archetypal instances. | You are designing how information should be managed within an information collection. |
INFORMATION NODE | What is the appropriate IT infrastructure to host information collections and information processes? | Related information processes and information collections should be hosted together in a server. | You are selecting the type of system to host information and its related processing. |

Stored information is accessed through information services that locate the required information and format for the consumer. Information collections are logical groupings of stored information. Often the information is organized consistently within the collection. Approaches for identifying, structuring, locking, and storing information within an information collection are covered in the information entry pattern group.
Chapter 6, “Information in Motion,” covers the information flow and information request pattern groups for moving information between information nodes (see Table 1.6).
Table 1.6. Pattern Groups in Chapter 6
Lead Pattern Name and Icon | Lead Pattern Problem Statement | Lead Pattern Solution Summary | Start Here When... |
INFORMATION REQUEST | An information process needs to work with information located on a remote information node. | Open a communication link with the remote information node and synchronously exchange the information and associated commands using an agreed protocol. | You want to understand the data that flows between two communicating information nodes. |
INFORMATION FLOW | How do you implement the movement of information between two information nodes? | Use an information trigger to start an information process to control the movement of information. This information process is responsible for extracting the required information from the appropriate sources, reengineering it, and delivering it to the destination information nodes. | You are designing information integration jobs to move information between different systems. |
Chapter 7, “Information Processing,” covers the different kinds of information processes, along with the information triggers that start them, which are found in a typical organization’s IT systems (see Table 1.7).
Table 1.7. Pattern Groups in Chapter 7
Lead Pattern Name and Icon | Lead Pattern Problem Statement | Lead Pattern Solution Summary | Start Here When... |
INFORMATION TRIGGER | An information process must be started when a particular event occurs. | When the event is detected, trigger a mechanism that is able to request the initiation of the process on an appropriate information node. | You are considering how to start an information process. This information process may be providing a new business function or moving information between information collections. |
INFORMATION PROCESS | An organization has to process information to support one of its activities. | Formally define and implement the processing for that activity in an information node. Ensure this information node has access to the information it needs. | You want to understand existing processing and or design new processing of information. |
Another key concern for organizations with valuable information is how to protect it so it retains its quality and it is not misused or stolen. This is covered in Chapter 8, “Information Protection,” (see Table 1.8).
Table 1.8. Pattern Groups in Chapter 8
Lead Pattern Name and Icon | Lead Pattern Problem Statement | Lead Pattern Solution Summary | Start Here When... |
INFORMATION REENGINEERING STEP | An information process is not able to consume the information it needs, as currently exists. | Insert capability to transform the information so it is consumable by the information process. | You need to understand how information can be transformed to meet new requirements. |
INFORMATION GUARD | The organization’s information needs to be protected from inappropriate use and theft. | Insert mechanisms into the information supply chain to verify that the right people are only using information for authorized purposes. | You need to consider the alternatives for the security and privacy of your information. |
INFORMATION PROBE | The operation of an information supply chain needs to be monitored to ensure it is working properly. | Insert probes into key points in the information supply chain to gather measurements for further analysis. | You need to plan how information management should be monitored. |
The protection of information is something that must be designed holistically, considering the welfare of key information at all stages of its lifetime. It is then implemented through the deployment of small components throughout the systems, where each is responsible for protecting an aspect of the information. The patterns of information management break down the aspects of information protection into three pattern groups:
- INFORMATION REENGINEERING STEP—These patterns focus on maintaining the quality and format of information.
- INFORMATION GUARD—These patterns ensure authorized people and processes are using information for authorized purposes.
- INFORMATION PROBE—These patterns are used to monitor the use and movement of information. With these patterns, it is possible to detect issues in the management of information and correct it.
Want to Earn daily 500 to 800 USD
by selling High demand &
Ultra modern and novel Gadgets online ?
The information protection patterns are used as processing steps in both the information process and information service pattern groups where they transform, protect, or monitor information as it enters the organization; when it is stored; when it is sent between systems; when it is retrieved, updated, and eventually archived and deleted. Individually, they protect a single point in the processing—collectively, they protect the organization’s information throughout its entire life cycle.
The final pattern group in Chapter 9, “Solutions for Information Management,” covers solutions that tackle different aspects of how information management can be improved. They use the pattern groups described previously as components (see Table 1.9).
Table 1.9. Pattern Groups in Chapter 9
Lead Pattern Name and Icon | Lead Pattern Problem Statement | Lead Pattern Solution Summary | Start Here When... |
INFORMATION SOLUTION | An organization recognizes there is a missing capability or a major issue with the way it manages an aspect of its information. | Create a project, or series of projects, to transform the way the information is managed by the organization’s people and information systems. | You want to plan changes to your information systems to improve information management. |
Summary
This chapter introduced some of the information management challenges an organization faces. Their applications provide the information processes that drive the business. These processes need access to a variety of information to perform their function. This information is distributed and duplicated among the applications and the challenge is to keep this information synchronized while ensuring it is available and suitably structured for all of the organization’s needs.
This chapter also introduced the patterns of information management. The patterns of information management are a collection of software design patterns that describe best practices for blending software components together to manage the typical information management challenges that organizations face. These patterns each have a succinct name and icon for use in design discussions. Each pattern also has a tabulated short description called a patlet and a full description that explains when to use it, how it works, and the consequences of using it.
Throughout the pattern language, this book uses a fictitious company called MCHS Trading to illustrate the use of the patterns. The patterns are also grouped together around particular information management topics called pattern groups. Each pattern group has a lead pattern that describes the basic mechanism at work and the rest of the patterns in the group are variations of this basic pattern.
The first lead pattern for a pattern group that was introduced was information provisioning. This explained the layers of components used to provide information to the organization. We then went on to explain how the pattern language is structured and where each of the pattern groups are located in the book.
Now that you have seen the pattern groups in the pattern language, you can choose to navigate directly to the patterns of interest. Alternatively, Chapter 2 describes how MCHS Trading used the patterns to transform its information systems through a series of projects.
---------------------------------------------------------------------------------
this was taken from the following book

https://itexamtools.com/what-is-the-difference-between-python-and-ruby/ |
https://itexamtools.com/7-skills-employers-of-the-future-will-be-looking-for/ |
https://itexamtools.com/aws-masterclass-go-serverless-with-aws-lambda-aws-aurora/ |
https://itexamtools.com/azure-fundamentals-how-to-pass-the-az-900-exam/ |
https://itexamtools.com/what-is-a-business-intelligence-dashboard/ https://itexamtools.com/livpure-product-review/ https://itexamtools.com/ikaria-lean-belly-juice-product-review/ https://itexamtools.com/master-of-applied-data-science-university-of-michigan/ https://itexamtools.com/exploring-ethereum-revolutionizing-the-world-through-decentralization/ https://itexamtools.com/google-data-analytics-professional-certificate https://www.linkedin.com/pulse/technology-migrations-unglamorous-obligation https://www.linkedin.com/pulse/introducing-udacity-management-platform |
Want to Earn daily 500 to 800 USD
by selling High demand &
Ultra modern and novel Gadgets online ?











No comments: